Spark 的RPC是通过Akka类库实现的,Akka用Scala语言开发,基于Actor并发模型实现
”scala spark 大数据 并发编程 多线程“ 的搜索结果
非结构化数据一般指大家文字型数据,但是数据中有很多诸如时间,数字等的信息。内建功能:Spark提供了丰富的内建功能,如机器学习库(MLlib)、图计算库(GraphX)和流处理库(Spark Streaming)等,这些功能使得...
scala 是一门以 jvm 为运行环境的静态类型编程语言,具备面向对象及函数式编程的特性 六大特征 Java 和 scala 可以混编 类型推测(自动推测类型) 并发和分布式( Actor ) 特质,特征(类似 java 中 ...
在学习大数据之初,很多人都会对编程语言的学习有疑问,比如说大数据编程主要用什么语言,在实际运用当中,大数据主流编程是Java,但是涉及到Spark、Kafka框架,还需要懂Scala。今天的大数据入门分享,我们就来对...
第66讲:Scala并发编程实战初体验及其在Spark源码中的应用解析笔记 程序宏大时java并发编程变得非常复杂, java并发编程的理念是:基于共享数据和加锁的线程模型 --若干程序访问共享数据,用监视器监控共享数据的...
Spark最初由美国加州伯克利大学( UC Berkelcy)的AMP实验室于2009年开发,是基于内存计算的大数据并行计算框架,可用于构建大型的、低延迟的数据分析应用程序。

大数据工程师学习计划.pdf
标签: 文档资料
2)Java ⾼级学习(《深⼊理解Java虚拟机》、《Java⾼并发实战》)---30⼩时 掌握多线程。 掌握并发包下的队列。 了解JMS。 掌握JVM技术。 掌握反射和动态代理。 3)Zookeeper学习 Zookeeper分布式协调服务介绍。 ...
大数据专家已经意识到Spark和Python在标准JVM上的重要性,但是围绕“ Scala或Python是大数据项目中的哪个选择”这一话题存在着共同的争论。两者之间的差异可以根据性能,学习曲线,并发性,类型安全性,可用性及其...
Apache Spark,全称伯克利数据分析栈,是一个开源的基于内存的通用分布式计算引擎,内部集成大量的通用算法,包括通用计算、机器学习、图计算等,用于处理大数据应用。主要由下面几个核心构件组成,具体包括:集群...
1、Scala中问什么没有多继承? 因为子类中容易造成变量的定义混乱。 2、Scala的函数与Java相比有什么差别? 跟Java相比,Scala函数类似于静态方法,但是却不需要依赖某个具体的类,Java中就算是静态方法也需要类名...
在大数据如日中天的当今,开发中只会调用 API 是远远不够的,火热的 Spark、Flink 被越来越多的人掌握,这就驱使技术人员向技术中更深层次的知识去挖掘,今天我们就一起聊聊分布式计算和通信实现技术 AKKA,到底依靠...

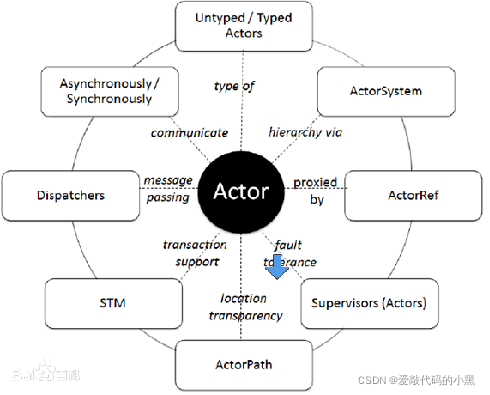
命令式编程涉及多线程之间的状态共享,需要锁机制实现并发控制;函数式编程不会在多个线程之间共享状态,不需要用锁机制,可以更好并行处理,充分利用多核CPU并行处理能力。 2.Scala语言 答: Scala是一门类java的多...
Apache Spark是一个开源的、强大的分布式查询和处理引擎,它提供MapReduce的灵活性和可扩展性,但速度明显要快上很多;拿数据存储在内存中的时候来说,它比Apache Hadoop 快100倍,访问磁盘时也要快上10倍。
java多线程同时访问一个加锁数据时易发生死锁 scala的并发编程:actor。与java实现方式完全不同,actor不共享数据,依赖消息传递 A传给B消息,B不停看收件箱。 B看到邮件后处理。 import scala.actors.Actor ...
Spark 最新的特性以及功能 2015 年中 Spark 版本从 1.2.1 升级到当前最新的 1.5.2,1.6.0 版本也马上要进行发布,每个版本都包含了许多的新特性以及重要的性能改进,我会按照时间顺序列举部分改进出来,希望大家对 ...
Hadoop/Spark是源自头部互联网企业的重型解决方案,适合需要有超大规模集群的巨大企业。很多场景的数据虽然也不少,但小集群甚至无集群就足够处理,远没多到这些巨大企业的规模,也没有那么多的硬件设备和维护人员。...

1、准备数据,2个文件 words.txt 内容: lilei hello zhangsan hello lisi hello 苏三 hello words.log 内容: lilei hello ...2、环境Intellj IDEA scala插件 3、代码 package p1 import
MapReduce为大数据处理提供了一种编程模型——分片-映射-归约。但是由于HDFS和MapReduce都是单线程模型,因此导致其不适用于大规模数据的并行计算场景。此外,为了更好地利用多核CPU资源,也需要提升Hadoop运行效率...
1. Scala语言概述 1.1 计算机的起源 阿隆佐邱奇设计了演算的系统,形式系统。 阿兰图灵提出图灵机。 冯诺依曼是计算机体系结构的奠基者。...命令式编程中,线程之间会共享一些变量,为了保持变

1)receive中case不匹配时,此actor可能被一些无关的消息占满而无法接收更多消息, 所以在实际编程时用case _ 方式, 2)消息发送是异步的。消息何时到达无法保证,所以写程序时不应该依赖于消息传来的顺序。 3)...
集成性:Scala 是一种运行在 Java 虚拟机(JVM)上的静态类型编程语言,可以与 Java 代码无缝集成。由于 Spark 涉及到与大量 Java 生态系统的交互,例如 Hadoop、Hive 等,使用 Scala 可以方便地与这些组件进行集成...

Scala系列——Akka并发编程
标签: 大数据


推荐文章
- 机器学习之超参数优化 - 网格优化方法(随机网格搜索)_网格搜索参数优化-程序员宅基地
- Lumina网络进入SDN市场-程序员宅基地
- python引用传递的区别_php传值引用的区别-程序员宅基地
- 《TCP/IP详解 卷2》 笔记: 简介_tcpip详解卷二有必要看吗-程序员宅基地
- 饺子播放器Jzvd使用过程中遇到的问题汇总-程序员宅基地
- python- flask current_app详解,与 current_app._get_current_object()的区别以及异步发送邮件实例-程序员宅基地
- 堪比ps的mac修图软件 Pixelmator Pro 2.0.6中文版 支持Silicon M1_pixelmator堆栈-程序员宅基地
- 「USACO2015」 最大流 - 树上差分_usaco 差分-程序员宅基地
- Leetcode #315: 计算右侧小于当前元素的个数_找元素右边比他小的数字-程序员宅基地
- HTTP图解读书笔记(第六章 HTTP首部)响应首部字段_web响应的首部内容-程序员宅基地